Dlaczego warto płacić więcej za uczenie maszynowe?

Przyspiesz swoje niezrównoważone obciążenia związane z nauką dzięki rozszerzeniu Intel dla Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb i Jui Mhatre, Intel Corporation
Niedawny blog NVIDIA przykuł naszą uwagę swoimi wprowadzającymi w błąd wynikami . Jaki jest sens porównywać procesor graficzny A100 z dziewięcioletnim procesorem (Intel Xeon E5-2698 został wprowadzony na rynek w 2014 roku i od tego czasu został wycofany) lub porównywać zoptymalizowany kod CUDA (biblioteka RAPIDS cuML) z niezoptymalizowanym, jednowątkowym Kod Pythona (standardowy scikit-learn z biblioteką niezrównoważonego uczenia się ), chyba że celowo próbujesz zawyżać przyspieszenie GPU w stosunku do procesora? Biblioteka niezrównoważonego uczenia się obsługuje estymatory kompatybilne z nauką scikit, więc do przyspieszenia użyli estymatorów cuML. Możemy użyć zoptymalizowanych estymatorów w Intel Extension dla Scikit-learn , po prostu dodając wywołanie patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Porównanie wydajności
Rozszerzenie Intel dla Scikit-learn zapewnia przyspieszenie we wszystkich tych samych testach porównawczych, co Nvidia (rysunek 1). Przyspieszenia wahają się od ~2x do ~140x w zależności od algorytmu i parametrów. Zauważ, że w standardowej bibliotece scikit-learn zabrakło pamięci dla testów porównawczych SMOTE i ADASYN „100 funkcji, 5 klas”. Jeśli wydajność ma znaczenie, wyniki te pokazują, że rozszerzenie Intel dla Scikit-learn zapewnia znaczne przyspieszenie w stosunku do standardowego scikit-learn.

Jak to się ma do wyników Nvidii A100? Przyjrzyjmy się dwóm algorytmom, w których Nvidia osiągnęła najwyższe przyspieszenia w porównaniu z uczeniem scikit: SVMSMOTE i CondensedNearestNeighbours (Rysunek 2). Wyniki te pokazują, że nasza wydajność jest na podobnym rzędzie wielkości jak cuML, gdy do porównania używany jest nowszy procesor i zoptymalizowane uczenie się scikit. Intel Extension for Scikit-learn nawet przewyższa cuML w niektórych testach. Porozmawiajmy teraz o cenie.


Porównanie kosztów
Warto zauważyć, że godzinowy koszt instancji a2-highgpu-1g A100 w GCP jest o 60% wyższy niż instancji n2-highcpu-64 (tabela 1). Oznacza to, że instancja A100 musi zapewniać co najmniej 1,6-krotne przyspieszenie w porównaniu z instancją Xeon Gold 6268CL (n2-highcpu-64), aby była konkurencyjna cenowo. (A100 zużywa również 1,7x i 1,2x więcej energii niż odpowiednio Xeon E5-2696 v4 i Xeon Gold 6268CL, ale na razie odłóżmy to na bok, ponieważ zużycie energii jest wliczone w koszt instancji).
Porównajmy stosunek ceny do wydajności w benchmarkach wybranych przez Nvidię , aby zobaczyć, czy instancja A100 uzasadnia swoją wyższą cenę. Całkowity koszt (USD) uruchomienia testu porównawczego to po prostu koszt instancji na godzinę (USD/godz.) razy czas działania (godz.). Szczegółowe porównanie kosztów pokazuje, że przeprowadzanie tych testów porównawczych na instancji Xeon jest często bardziej opłacalną opcją (rysunek 3). Na poniższych wykresach wartość większa od jedności wskazuje, że dany benchmark jest droższy na instancji A100. Na przykład wartość 1,29 oznacza, że instancja A100 jest o 29% droższa niż instancja Xeon.



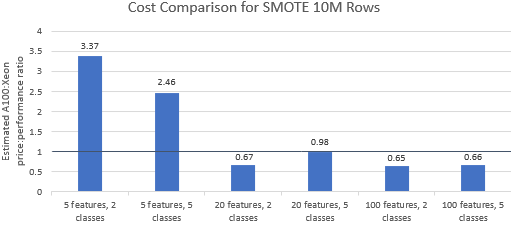
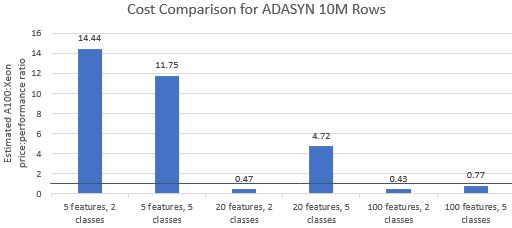
Koszt testu porównawczego różni się w zależności od zastosowanego algorytmu i parametrów, ale wyniki generalnie przemawiają za instancją Xeon: średnia geometryczna kosztu jest większa niż jeden dla czterech z pięciu algorytmów, a ogólna średnia geometryczna wynosi 1,36 (Tabela 2).

Ponadto procesory oferują większą elastyczność w wyborze instancji, co dodatkowo poprawia wydajność. Bardziej opłacalne jest wybranie najmniejszej zdolnej instancji Xeon, która może obsłużyć dany rozmiar problemu, jednocześnie spełniając wymagania dotyczące wydajności i ograniczeń budżetowych. Rysunek 4 pokazuje jeden taki przykład dla dwóch najmniejszych benchmarków. Wyniki te pokazują, że uruchomienie na sprzęcie, który najlepiej odpowiada potrzebom konfiguracji modelu, może być znacznie tańsze. Na przykład uruchomienie dwóch testów porównawczych ADASYN z rozszerzeniem Intel dla Scikit-learn na instancji e2-highcpu-8 to tylko 1,5% i 2,1% kosztu uruchomienia cuML na instancji A100.

Wniosek
Powyższe wyniki pokazują, że rozszerzenie Intel dla Scikit-learn jest w stanie radykalnie poprawić wyniki wydajności w porównaniu do standardowego scikit-learn, a także może przewyższyć wydajność A100 w niektórych testach. Biorąc pod uwagę koszty, wyniki Intel Extension for Scikit-learn są jeszcze korzystniejsze, ponieważ instancje Xeon są o wiele tańsze niż instancje A100. Użytkownicy mogą wybrać instancję Xeon, która spełnia ich wymagania dotyczące wydajności, mocy i ceny.

![Czym w ogóle jest lista połączona? [Część 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































