Wykorzystanie mocy wielordzeniowej z Asyncio w Pythonie

To jest jeden z moich artykułów w kolumnie Python Concurrency , a jeśli uznasz go za przydatny, możesz przeczytać resztę tutaj .
Wstęp
W tym artykule pokażę, jak wykonać kod asyncio Pythona na wielordzeniowym procesorze, aby odblokować pełną wydajność współbieżnych zadań.
Jaki jest nasz problem?
asyncio używa tylko jednego rdzenia.
W poprzednich artykułach szczegółowo omówiłem mechanikę używania asyncio w Pythonie. Dzięki tej wiedzy możesz dowiedzieć się, że asyncio umożliwia wykonywanie zadań związanych z IO z dużą szybkością poprzez ręczne przełączanie wykonywania zadań w celu ominięcia procesu rywalizacji GIL podczas wielowątkowego przełączania zadań.
Teoretycznie czas wykonywania zadań związanych z IO zależy od czasu od zainicjowania do odpowiedzi operacji IO i nie zależy od wydajności procesora. W ten sposób możemy jednocześnie inicjować dziesiątki tysięcy zadań IO i szybko je realizować.
Ale ostatnio pisałem program, który musiał indeksować dziesiątki tysięcy stron internetowych jednocześnie i odkryłem, że chociaż mój program asyncio był znacznie wydajniejszy niż programy wykorzystujące iteracyjne indeksowanie stron internetowych, nadal wymagał długiego oczekiwania. Czy powinienem wykorzystywać pełną wydajność komputera? Otworzyłem więc Menedżera zadań i sprawdziłem:
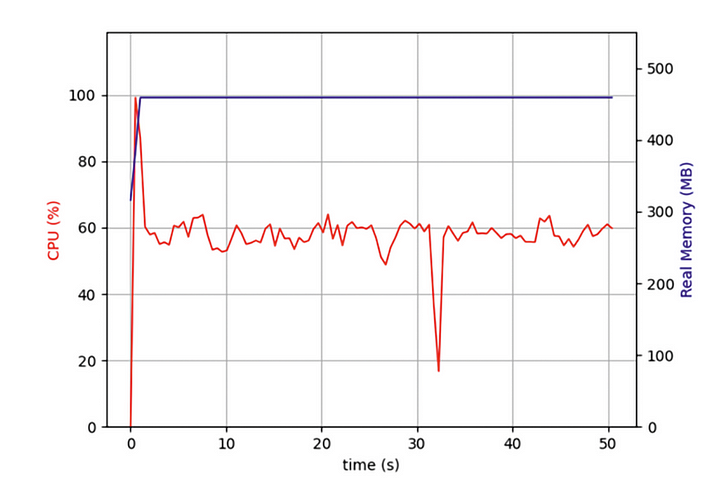
Odkryłem, że od początku mój kod działał tylko na jednym rdzeniu procesora, a kilka innych rdzeni było bezczynnych. Oprócz uruchamiania operacji IO w celu pobrania danych sieciowych, zadanie musi rozpakować i sformatować dane po ich zwróceniu. Chociaż ta część operacji nie zużywa dużo wydajności procesora, po większej liczbie zadań te operacje związane z procesorem będą miały poważny wpływ na ogólną wydajność.
Chciałem, aby moje współbieżne zadania asyncio były wykonywane równolegle na wielu rdzeniach. Czy to zmniejszy wydajność mojego komputera?
Podstawowe zasady asyncio
Aby rozwiązać tę zagadkę, musimy zacząć od podstawowej implementacji asyncio, czyli pętli zdarzeń.

Jak pokazano na rysunku, poprawa wydajności programów asyncio zaczyna się od zadań intensywnie korzystających z operacji we/wy. Zadania intensywnie korzystające z IO obejmują żądania HTTP, odczytywanie i zapisywanie plików, uzyskiwanie dostępu do baz danych itp. Najważniejszą cechą tych zadań jest to, że procesor nie blokuje się i spędza dużo czasu na obliczeniach podczas oczekiwania na zwrócenie danych zewnętrznych, co jest bardzo różni się od innej klasy zadań synchronicznych, które wymagają ciągłego zajętości procesora w celu obliczenia określonego wyniku.
Kiedy generujemy partię zadań asyncio, kod najpierw umieszcza te zadania w kolejce. W tym momencie istnieje wątek zwany pętlą zdarzeń, który pobiera jedno zadanie z kolejki i wykonuje je. Kiedy zadanie dotrze do instrukcji await i czeka (zwykle na zwrot żądania), pętla zdarzeń pobiera kolejne zadanie z kolejki i wykonuje je. Dopóki poprzednio oczekujące zadanie nie otrzyma danych przez wywołanie zwrotne, pętla zdarzeń powraca do poprzedniego zadania oczekującego i kończy wykonywanie pozostałej części kodu.
Ponieważ wątek pętli zdarzeń jest wykonywany tylko na jednym rdzeniu, pętla zdarzeń blokuje się, gdy „reszta kodu” zajmuje czas procesora. Gdy liczba zadań w tej kategorii jest duża, każdy mały segment blokujący sumuje się i spowalnia program jako całość.
Jakie jest moje rozwiązanie?
Z tego wiemy, że programy asyncio zwalniają, ponieważ nasz kod Pythona wykonuje pętlę zdarzeń tylko na jednym rdzeniu, a przetwarzanie danych IO powoduje spowolnienie programu. Czy istnieje sposób na rozpoczęcie pętli zdarzeń na każdym rdzeniu procesora, aby ją wykonać?
Jak wszyscy wiemy, począwszy od Pythona 3.7, zaleca się, aby cały kod asyncio był wykonywany przy użyciu metody asyncio.run, która jest abstrakcją wysokiego poziomu, która wywołuje pętlę zdarzeń w celu wykonania kodu jako alternatywy dla następującego kodu:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
W poprzednim artykule użyto rzeczywistego przykładu, aby wyjaśnić użycie loop.run_in_executormetody asyncio do zrównoleglenia wykonywania kodu w puli procesów, jednocześnie uzyskując wyniki każdego procesu podrzędnego z procesu głównego. Jeśli nie czytałeś poprzedniego artykułu, możesz go przeczytać tutaj:
W ten sposób powstaje nasze rozwiązanie: rozdzielić wiele współbieżnych zadań na wiele podprocesów przy użyciu wykonywania wielordzeniowego za pomocą metody loop.run_in_executor, a następnie wywołać asyncio.runkażdy podproces w celu uruchomienia odpowiedniej pętli zdarzeń i wykonania współbieżnego kodu. Poniższy diagram przedstawia cały przepływ:
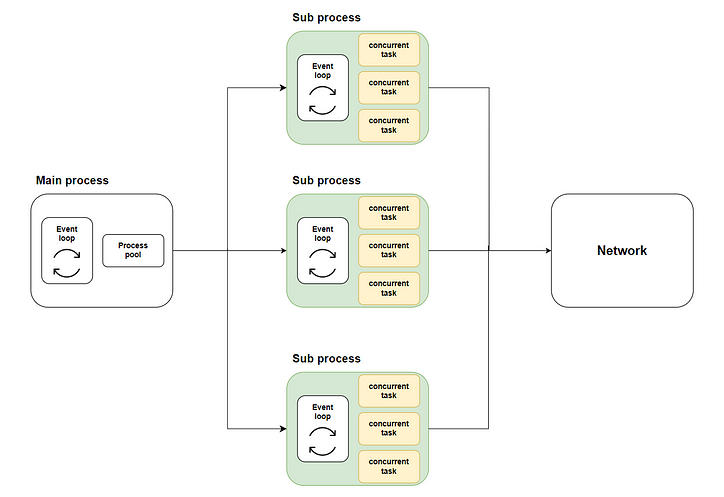
Gdzie zielona część reprezentuje podprocesy, które rozpoczęliśmy. Żółta część reprezentuje współbieżne zadania, które rozpoczęliśmy.
Przygotowanie przed startem
Symulacja realizacji zadania
Zanim będziemy mogli rozwiązać problem, musimy się przygotować, zanim zaczniemy. W tym przykładzie nie możemy napisać rzeczywistego kodu do indeksowania zawartości sieci, ponieważ byłoby to bardzo irytujące dla witryny docelowej, więc zasymulujemy nasze prawdziwe zadanie za pomocą kodu:
Jak pokazuje kod, najpierw używamy asyncio.sleepdo symulacji powrotu zadania IO w losowym czasie i iteracyjnego sumowania do symulacji przetwarzania procesora po zwróceniu danych.
Efekt tradycyjnego kodu
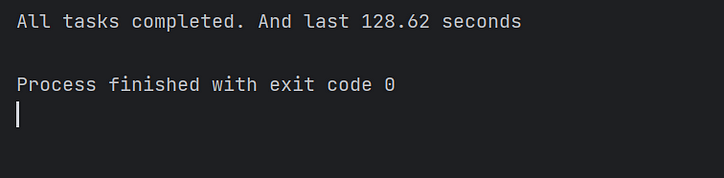
Następnie stosujemy tradycyjne podejście polegające na uruchamianiu 10 000 współbieżnych zadań w metodzie głównej i obserwujemy czas zużywany przez tę partię współbieżnych zadań:
Jak widać na rysunku, wykonywanie zadań asyncio z tylko jednym rdzeniem zajmuje więcej czasu.
Implementacja kodu
Następnie zaimplementujmy wielordzeniowy kod asyncio zgodnie ze schematem blokowym i sprawdźmy, czy wydajność uległa poprawie.
Projektowanie ogólnej struktury kodu
Po pierwsze, jako architekt, nadal musimy najpierw zdefiniować ogólną strukturę skryptu, jakie metody są wymagane i jakie zadania musi wykonać każda metoda:
Konkretna implementacja każdej metody
Następnie zaimplementujmy każdą metodę krok po kroku.
Metoda query_concurrentlyuruchomi określoną partię zadań jednocześnie i uzyska wyniki za pomocą asyncio.gathermetody:
Metoda run_batch_tasksnie jest metodą asynchroniczną, ponieważ jest uruchamiana bezpośrednio w procesie potomnym:
Wreszcie jest nasza mainmetoda. Ta metoda wywoła loop.run_in_executormetodę, aby run_batch_taskswykonać metodę w puli procesów i scalić wyniki wykonania procesu potomnego w listę:
Ponieważ piszemy skrypt wieloprocesowy, musimy użyć, if __name__ == “__main__”aby uruchomić główną metodę w głównym procesie:
Wykonaj kod i zobacz wyniki
Następnie uruchamiamy skrypt i patrzymy na obciążenie każdego rdzenia w menedżerze zadań:
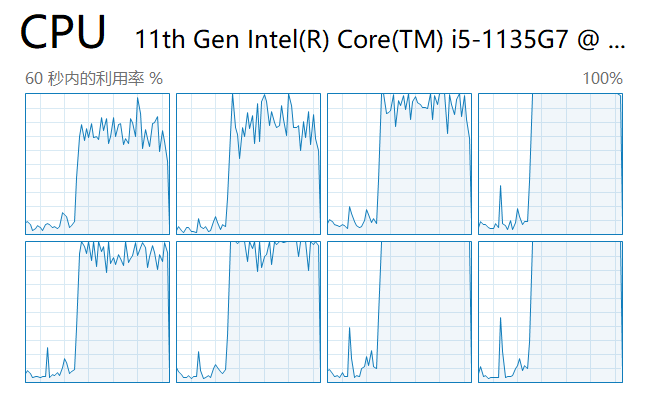
Jak widać, wszystkie rdzenie procesora są wykorzystane.
Na koniec obserwujemy czas wykonania kodu i potwierdzamy, że wielowątkowy kod asyncio rzeczywiście kilkukrotnie przyspiesza wykonanie kodu! Misja wykonana!

Wniosek
W tym artykule wyjaśniłem, dlaczego asyncio może jednocześnie wykonywać zadania intensywnie korzystające z operacji we/wy, ale nadal trwa to dłużej niż oczekiwano, gdy uruchamiane są duże partie współbieżnych zadań.
Dzieje się tak dlatego, że w tradycyjnym schemacie implementacji kodu asyncio pętla zdarzeń może wykonywać zadania tylko na jednym rdzeniu, a pozostałe rdzenie są w stanie bezczynności.
Dlatego zaimplementowałem rozwiązanie, które umożliwia osobne wywoływanie każdej pętli zdarzeń na wielu rdzeniach w celu równoległego wykonywania współbieżnych zadań. I wreszcie znacznie poprawiło wydajność kodu.
Ze względu na ograniczenia moich możliwości rozwiązanie w tym artykule nieuchronnie ma niedoskonałości. Zapraszam do komentarzy i dyskusji. Aktywnie odpowiem za Ciebie.

![Czym w ogóle jest lista połączona? [Część 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































