Łatwa inżynieria danych — dołączone skrypty w języku Python ułatwiające rozpoczęcie zadań ETL
Przegląd:
Przyjmij pracę inżyniera danych, wyodrębniając dane z wielu źródeł w formatach plików, przekształcając je w określone typy danych i ładując je do jednego źródła w celu analizy. Wkrótce Po przeczytaniu tego artykułu za pomocą kilku praktycznych przykładów będziesz mógł przetestować swoje umiejętności, wdrażając web scraping i wyodrębniając dane za pomocą interfejsów API. Dzięki Pythonowi i inżynierii danych będziesz mógł zacząć gromadzić ogromne zbiory danych z wielu źródeł i przekształcać je w jedno podstawowe źródło lub rozpocząć przeglądanie sieci w celu uzyskania przydatnych informacji biznesowych.

Streszczenie:
- Dlaczego inżynieria danych jest bardziej niezawodna?
- Proces cyklu ETL
- Krok po kroku Wyodrębnij, przekształć, funkcję Load
- O inżynierii danych
- Wniosek
Jest to bardziej niezawodny i najszybciej rozwijający się zawód technologiczny w obecnej generacji, ponieważ koncentruje się bardziej na skrobaniu sieci i przeszukiwaniu zestawów danych.
Proces (cykl ETL):
Czy zastanawiałeś się kiedyś, jak zintegrowano dane z wielu źródeł, aby stworzyć jedno źródło informacji? Przetwarzanie wsadowe to rodzaj zbierania danych i dowiedz się więcej o tym, „jak zbadać rodzaj przetwarzania wsadowego” o nazwie Wyodrębnij, Przekształć i Załaduj.

ETL to proces wyodrębniania ogromnych ilości danych z różnych źródeł i formatów oraz konwertowania ich do jednego formatu przed umieszczeniem ich w bazie danych lub pliku docelowym.
Część Twoich danych jest przechowywana w plikach CSV, a część w plikach JSON. Musisz zebrać wszystkie te informacje w jednym pliku, aby AI mogła je odczytać. Ponieważ twoje dane są w jednostkach imperialnych, ale sztuczna inteligencja potrzebuje jednostek metrycznych, musisz je przekonwertować. Ponieważ sztuczna inteligencja może odczytywać dane CSV tylko w jednym dużym pliku, musisz go najpierw załadować. Jeśli dane są w formacie CSV, umieśćmy następujący ETL z pythonem i spójrzmy na krok ekstrakcji z kilkoma prostymi przykładami.
Przeglądając listę plików .json i .csv. Rozszerzenie pliku glob jest poprzedzone gwiazdką i kropką na wejściu. Zwracana jest lista plików .csv. W przypadku plików .json możemy zrobić to samo. Możemy utworzyć plik, który wyodrębnia imiona, wzrosty i wagi w formacie CSV. Nazwa pliku .csv to dane wejściowe, a dane wyjściowe to ramka danych. W przypadku formatów JSON możemy zrobić to samo.
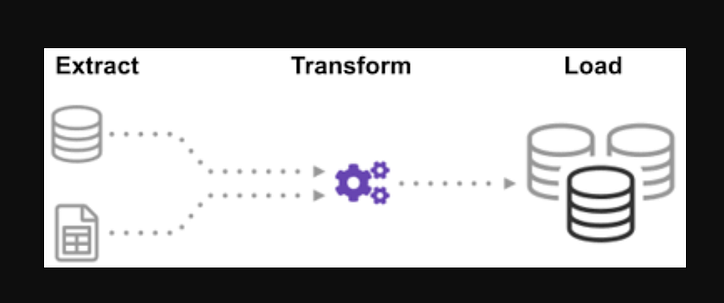
Krok 1:
Zaimportuj funkcje i wymagane moduły
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Pliki dealership_datazawierają pliki CSV, JSON i XML dla danych używanych samochodów, które zawierają funkcje o nazwach car_model, year_of_manufacture, pricei fuel. Więc zamierzamy wyodrębnić plik z surowych danych i przekształcić go w plik docelowy i załadować go do wyjścia.
Ustaw ścieżkę dla plików docelowych:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
Funkcja będzie wyodrębniać duże ilości danych z wielu źródeł w partiach. Dodając tę funkcję, teraz wykryje i załaduje wszystkie nazwy plików CSV, a pliki CSV zostaną dodane do ramki daty z każdą iteracją pętli, przy czym pierwsza iteracja jest dołączana jako pierwsza, a następnie druga iteracja, w wyniku na liście wyodrębnionych danych. Po zebraniu danych przejdziemy do etapu „Przekształcenia” procesu.
Uwaga: Jeśli parametr „ignore index” jest ustawiony na wartość true, kolejność każdego wiersza będzie taka sama, jak kolejność dołączania wierszy do ramki danych.
Funkcja wyodrębniania CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Teraz wywołaj funkcję wyodrębniania, używając jej wywołania funkcji dla CSV , JSON , XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Po zebraniu danych przejdziemy do fazy „Przekształcenia” procesu. Ta funkcja przekonwertuje wysokość kolumny wyrażoną w calach na milimetry, a kolumnę wyrażoną w funtach na kilogramy i zwróci wyniki w postaci zmiennych danych. W wejściowej ramce danych wysokość kolumny jest wyrażona w stopach. Przekształć kolumnę, aby przekonwertować ją na metry i zaokrąglić do dwóch miejsc po przecinku.
def transform(data):
data['price'] = round(data.price, 2)
return data
Nadszedł czas, aby załadować dane do pliku docelowego teraz, gdy je zebraliśmy i określiliśmy. W tym scenariuszu zapisujemy ramkę danych pandy jako plik CSV. Przeszliśmy już przez etapy wyodrębniania, przekształcania i ładowania danych z różnych źródeł do pojedynczego pliku docelowego. Musimy ustanowić wpis w dzienniku, zanim będziemy mogli zakończyć naszą pracę. Osiągniemy to, pisząc funkcję rejestrującą.
Funkcja ładowania:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Wszystkie zapisane dane zostaną dołączone do aktualnych informacji po dodaniu „a”. Możemy następnie dołączyć znacznik czasu do każdej fazy procesu, wskazując, kiedy się zaczyna i kiedy kończy, generując tego typu wpis. Po zdefiniowaniu całego kodu wymaganego do wykonania procesu ETL na danych, ostatnim krokiem jest wywołanie wszystkich funkcji.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Najpierw zaczynamy od wywołania funkcji extract_data. Dane otrzymane z tego etapu zostaną następnie przeniesione do drugiego etapu przekształcania danych. Po zakończeniu dane są następnie ładowane do pliku docelowego. Należy również pamiętać, że przed i po każdym kroku dodano godzinę i datę rozpoczęcia i zakończenia.
Dziennik rozpoczęcia procesu ETL:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log("Rozpoczęła się faza transformacji")
przekształcone_dane = transformacja(wyodrębnione_dane)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- Jak napisać prostą funkcję Extract.
- Jak napisać prostą funkcję Transform.
- Jak napisać prostą funkcję Load.
- Jak napisać prostą funkcję rejestrującą.
Co najwyżej omówiliśmy wszystkie procesy ETL. Ponadto, zobaczmy, „jakie są korzyści z pracy inżyniera danych?”.
O inżynierii danych:
Inżynieria danych to rozległa dziedzina o wielu nazwach. W wielu instytucjach może nawet nie mieć formalnego tytułu. W rezultacie ogólnie lepiej jest zacząć od zdefiniowania celów pracy inżynierii danych, które prowadzą do oczekiwanych wyników. Użytkownicy, którzy polegają na inżynierach danych, są tak różnorodni, jak talenty i wyniki zespołów inżynierii danych. Twoi konsumenci zawsze będą określać, jakimi sprawami się zajmujesz i jak je rozwiązujesz, niezależnie od branży, w której działasz.
Wniosek:
Mam nadzieję, że znajdziesz w tym artykule pomoc i zrozumiesz, jak używać Pythona do ETL, gdy zaczynasz swoją podróż do nauki inżynierii danych. Chcesz dowiedzieć się więcej? Zachęcam do zapoznania się z moimi innymi artykułami o tym, jak można wykorzystać klasy Pythona do usprawnienia procesów inżynierii danych . Pokazuję również, jak wykorzystać pydantic do usprawnienia walidacji danych na jednym z pierwszych i najważniejszych etapów potoku danych. Jeśli interesuje Cię wizualizacja danych, zapoznaj się z tym przewodnikiem krok po kroku dotyczącym tworzenia pierwszego wykresu za pomocą Apache Superset .
Wezwanie do działania
Jeśli uznasz ten przewodnik za pomocny, nie wahaj się klaskać i podążać za mną. Dołącz do medium za pomocą tego linku , aby uzyskać dostęp do wszystkich artykułów premium ode mnie i wszystkich innych niesamowitych pisarzy tutaj na medium.
Kodowanie na wyższym poziomie
Dziękujemy za bycie częścią naszej społeczności! Zanim pójdziesz:
- Klaskajcie za relację i śledźcie autora
- Zobacz więcej treści w publikacji Level Up Coding
- Śledź nas: Twitter | LinkedIn | Biuletyn Informacyjny

![Czym w ogóle jest lista połączona? [Część 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































