Hợp nhất gấu trúc 101
- Làm thế nào để thực hiện một (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINvới gấu trúc? - Làm cách nào để thêm NaN cho các hàng bị thiếu sau khi hợp nhất?
- Làm cách nào để loại bỏ NaN sau khi hợp nhất?
- Tôi có thể hợp nhất trên chỉ mục không?
- Tham gia chéo với gấu trúc?
- Làm cách nào để hợp nhất nhiều DataFrames?
merge?join?concat?update? WHO? Gì? Tại sao?!
... và nhiều hơn nữa. Tôi đã thấy những câu hỏi lặp lại này hỏi về các khía cạnh khác nhau của chức năng hợp nhất gấu trúc. Hầu hết thông tin liên quan đến hợp nhất và các trường hợp sử dụng khác nhau của nó ngày nay bị phân tán trong hàng chục bài đăng có từ ngữ xấu, không thể tìm kiếm được. Mục đích ở đây là đối chiếu một số điểm quan trọng hơn cho hậu thế.
QnA này có nghĩa là phần tiếp theo trong một loạt các hướng dẫn sử dụng hữu ích về các thành ngữ phổ biến của gấu trúc (xem bài đăng này về xoay và bài đăng này về nối , mà tôi sẽ đề cập sau).
Xin lưu ý rằng bài đăng này không nhằm mục đích thay thế cho tài liệu , vì vậy hãy đọc bài viết đó! Một số ví dụ được lấy từ đó.
Trả lời
Bài đăng này nhằm mục đích cung cấp cho người đọc sơ lược về cách hợp nhất theo hương vị SQL với gấu trúc, cách sử dụng nó và khi nào không nên sử dụng nó.
Cụ thể, đây là những gì bài đăng này sẽ trải qua:
Khái niệm cơ bản - các kiểu nối (LEFT, RIGHT, OUTER, INNER)
- hợp nhất với các tên cột khác nhau
- tránh trùng lặp cột khóa hợp nhất trong đầu ra
Hợp nhất với chỉ mục trong các điều kiện khác nhau
- sử dụng hiệu quả chỉ mục được đặt tên của bạn
- hợp nhất khóa làm chỉ mục của một và cột của một khác
Multiway hợp nhất trên các cột và chỉ mục (duy nhất và không duy nhất)
Các lựa chọn thay thế đáng chú ý cho
mergevàjoin
Những gì bài đăng này sẽ không trải qua:
- Các cuộc thảo luận và thời gian liên quan đến hiệu suất (hiện tại). Chủ yếu là đề cập đến các lựa chọn thay thế tốt hơn, bất cứ khi nào thích hợp.
- Xử lý các hậu tố, loại bỏ các cột thừa, đổi tên đầu ra và các trường hợp sử dụng cụ thể khác. Có những bài đăng khác (đọc: tốt hơn) giải quyết vấn đề đó, vì vậy hãy tìm hiểu!
Lưu ý
Hầu hết các ví dụ mặc định cho các hoạt động INNER JOIN trong khi thể hiện các tính năng khác nhau, trừ khi được chỉ định khác.Hơn nữa, tất cả các DataFrames ở đây có thể được sao chép và nhân rộng để bạn có thể chơi với chúng. Ngoài ra, hãy xem bài đăng này về cách đọc DataFrames từ khay nhớ tạm của bạn.
Cuối cùng, tất cả các biểu diễn trực quan của các hoạt động JOIN đã được vẽ tay bằng Google Bản vẽ. Cảm hứng từ đây .
Nói đủ rồi, chỉ cho tôi cách sử dụng merge!
Thiết lập
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
Để đơn giản, cột khóa có cùng tên (hiện tại).
Một bên tham gia được đại diện bởi
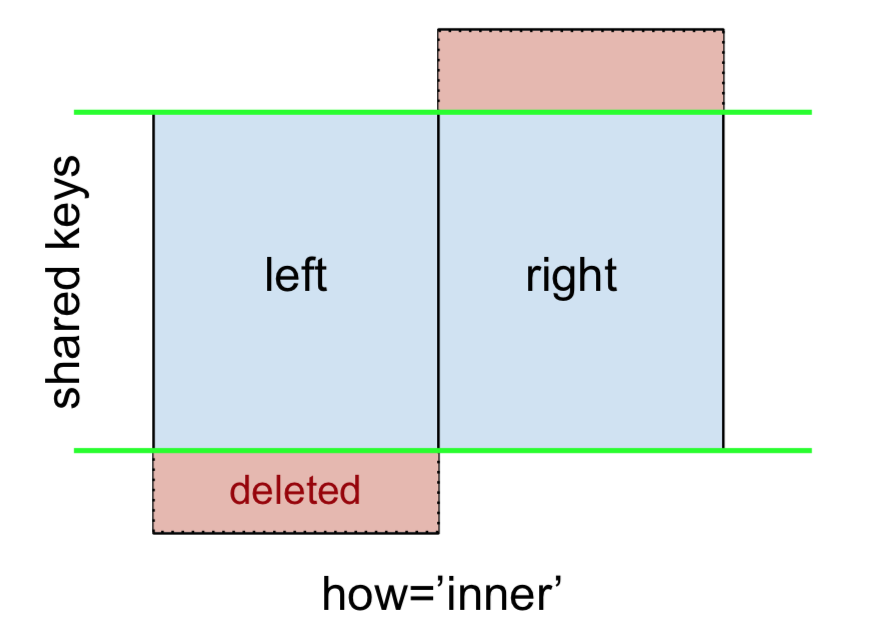
Lưu ý
Điều này, cùng với các số liệu sắp tới, tất cả đều tuân theo quy ước này:
- màu xanh lam cho biết các hàng có trong kết quả hợp nhất
- màu đỏ cho biết các hàng bị loại trừ khỏi kết quả (tức là đã bị loại bỏ)
- màu xanh lá cây cho biết các giá trị bị thiếu được thay thế bằng
NaNs trong kết quả
Để thực hiện INNER JOIN, hãy gọi mergeDataFrame bên trái, chỉ định DataFrame bên phải và khóa nối (ít nhất) làm đối số.
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Điều này chỉ trả về các hàng từ leftvà rightchia sẻ một khóa chung (trong ví dụ này là "B" và "D).
Một LEFT OUTER JOIN , hoặc LEFT JOIN được đại diện bởi
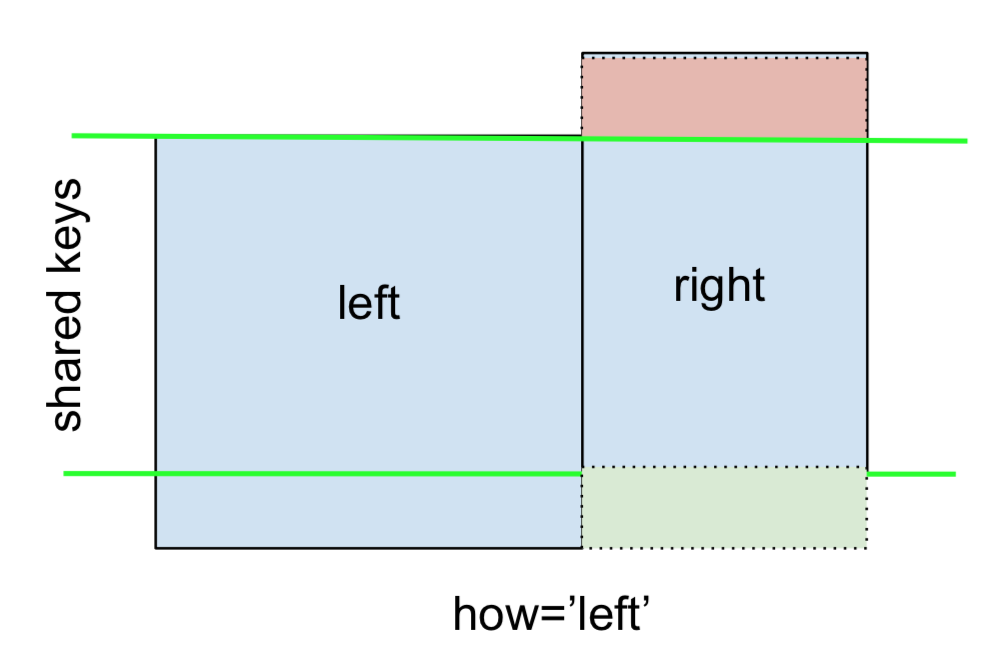
Điều này có thể được thực hiện bằng cách chỉ định how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Lưu ý cẩn thận vị trí của NaN ở đây. Nếu bạn chỉ định how='left', thì chỉ các khóa từ leftđược sử dụng và dữ liệu bị thiếu từ rightđược thay thế bằng NaN.
Và tương tự, đối với RIGHT OUTER JOIN , hoặc RIGHT JOIN là ...
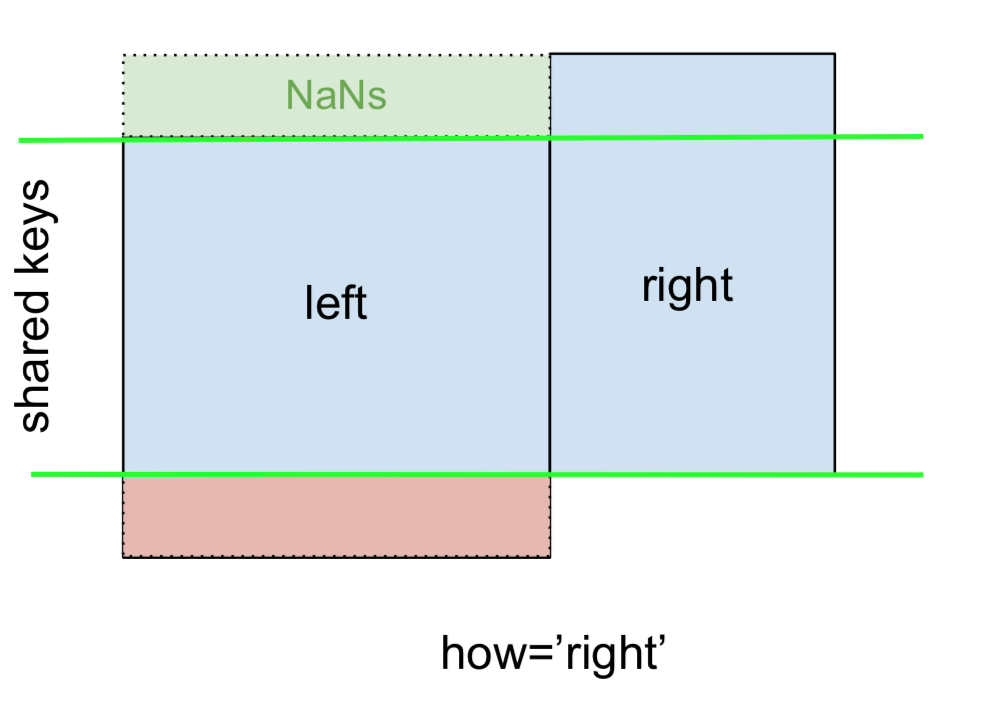
... chỉ định how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Ở đây, các khóa từ rightđược sử dụng và dữ liệu bị thiếu từ leftđược thay thế bằng NaN.
Cuối cùng, đối với FULL OUTER JOIN , được cung cấp bởi
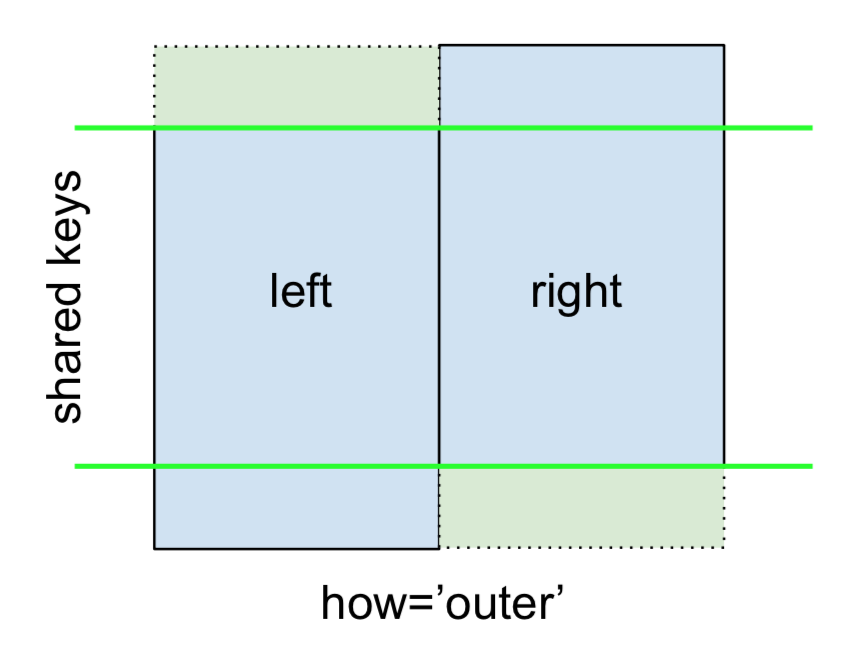
chỉ rõ how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
Điều này sử dụng các khóa từ cả hai khung và NaN được chèn cho các hàng bị thiếu trong cả hai.
Tài liệu tóm tắt các hợp nhất khác nhau này một cách độc đáo:

CÁC THAM GIA KHÁC - LEFT-Loại trừ, RIGHT-Loại trừ và FULL-Loại trừ / ANTI JOIN
Nếu bạn cần THAM GIA TRÁI-Loại trừ và PHẢI-Loại trừ THAM GIA trong hai bước.
Đối với LEFT-Excluding JOIN, được đại diện là
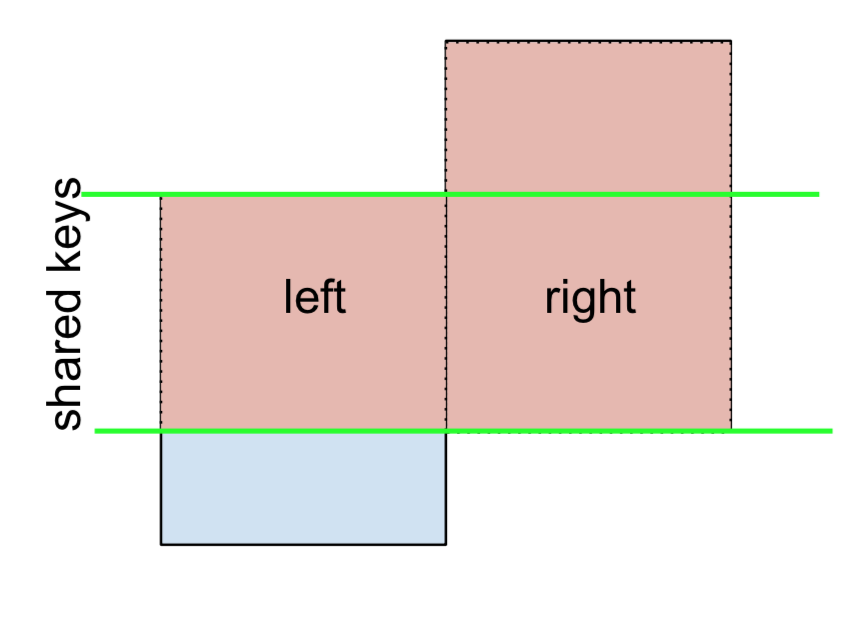
Bắt đầu bằng cách thực hiện THAM GIA LEFT OUTER và sau đó lọc (loại trừ!) Các hàng chỉ đến từ left,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Ở đâu,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothVà tương tự, đối với THAM GIA RIGHT-Loại trừ,
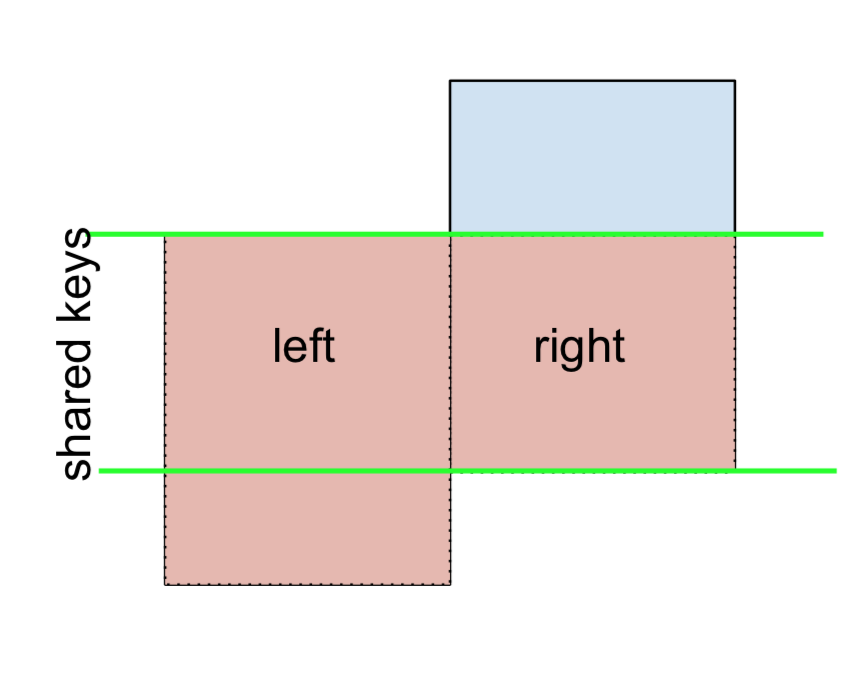
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Cuối cùng, nếu bạn được yêu cầu thực hiện hợp nhất chỉ giữ lại các khóa từ bên trái hoặc bên phải, chứ không phải cả hai (IOW, thực hiện ANTI-JOIN ),
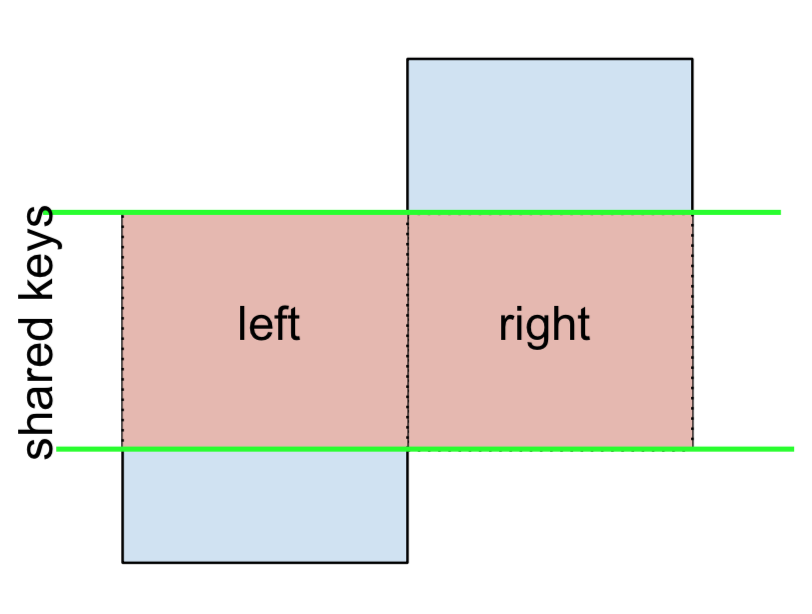
Bạn có thể làm điều này theo cách tương tự—
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Các tên khác nhau cho các cột chính
Nếu các cột chính được đặt tên khác nhau — ví dụ: lefthas keyLeft, and righthas keyRightthay vì key— thì bạn sẽ phải chỉ định left_onvà right_ondưới dạng các đối số thay vì on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Tránh trùng lặp cột khóa trong đầu ra
Khi hợp nhất keyLefttừ leftvà keyRighttừ right, nếu bạn chỉ muốn một trong hai keyLefthoặc keyRight(nhưng không phải cả hai) trong đầu ra, bạn có thể bắt đầu bằng cách đặt chỉ mục như một bước sơ bộ.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Đối chiếu điều này với đầu ra của lệnh ngay trước đó (tức là đầu ra của left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), bạn sẽ thấy keyLeftbị thiếu. Bạn có thể tìm ra cột nào cần giữ lại dựa trên chỉ mục của khung nào được đặt làm khóa. Điều này có thể quan trọng khi, chẳng hạn, thực hiện một số thao tác OUTER JOIN.
Chỉ hợp nhất một cột từ một trong các cột DataFrames
Ví dụ, hãy xem xét
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Nếu bạn được yêu cầu chỉ hợp nhất "new_val" (không có bất kỳ cột nào khác), bạn thường có thể chỉ tập hợp các cột trước khi hợp nhất:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Nếu bạn đang thực hiện THAM GIA LEFT OUTER, một giải pháp hiệu quả hơn sẽ bao gồm map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Như đã đề cập, điều này tương tự, nhưng nhanh hơn
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Hợp nhất trên nhiều cột
Để kết hợp trên nhiều cột, hãy chỉ định danh sách cho on(hoặc left_onvà right_on, nếu thích hợp).
left.merge(right, on=['key1', 'key2'] ...)
Hoặc, trong trường hợp tên khác nhau,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Các merge*hoạt động và chức năng hữu ích khác
Hợp nhất DataFrame với Chuỗi trên chỉ mục : Xem câu trả lời này .
Bên cạnh đó
merge,DataFrame.updatevàDataFrame.combine_firstcũng được sử dụng trong một số trường hợp nhất định để cập nhật DataFrame này với DataFrame khác.pd.merge_orderedlà một hàm hữu ích cho các JOIN có thứ tự.pd.merge_asof(đọc: merge_asOf) hữu ích cho các phép nối gần đúng .
Phần này chỉ bao gồm những điều rất cơ bản và được thiết kế để chỉ kích thích sự thèm ăn của bạn. Để biết thêm các ví dụ và các trường hợp, xem tài liệu hướng dẫn trên merge, joinvàconcat cũng như các liên kết đến các thông số kỹ thuật chức năng.
Dựa trên chỉ mục * -JOIN (+ cột chỉ mục merge)
Thiết lập
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
Thông thường, hợp nhất trên chỉ mục sẽ trông như thế này:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Hỗ trợ tên chỉ mục
Nếu chỉ mục của bạn được đặt tên, thì người dùng v0.23 cũng có thể chỉ định tên cấp cho on(hoặc left_onvà right_onnếu cần).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Hợp nhất trên chỉ mục của một, (các) cột của một
Có thể (và khá đơn giản) sử dụng chỉ mục của một và cột của một khác, để thực hiện hợp nhất. Ví dụ,
left.merge(right, left_on='key1', right_index=True)
Hoặc ngược lại ( right_on=...và left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
Trong trường hợp đặc biệt này, chỉ mục cho leftđược đặt tên, vì vậy bạn cũng có thể sử dụng tên chỉ mục với left_on, như sau:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
Bên cạnh những điều này, có một tùy chọn ngắn gọn khác. Bạn có thể sử dụng các giá trị DataFrame.joinmặc định để tham gia vào chỉ mục. DataFrame.jointheo mặc định có LEFT OUTER JOIN, vì vậy how='inner'cần thiết ở đây.
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Lưu ý rằng tôi cần chỉ định các đối số lsuffixvà rsuffixvì joinnếu không sẽ xảy ra lỗi:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Vì tên các cột giống nhau. Điều này sẽ không có vấn đề gì nếu chúng được đặt tên khác.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
Cuối cùng, để thay thế cho các phép nối dựa trên chỉ mục, bạn có thể sử dụng pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Bỏ qua join='inner'nếu bạn cần THAM GIA ĐẦY ĐỦ OUTER (mặc định):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
Để biết thêm thông tin, hãy xem bài đăng chuẩn này pd.concatcủa @piRSquared .
Tổng quát hóa: nhập mergenhiều DataFrames
Thông thường, tình huống phát sinh khi nhiều DataFrame được hợp nhất với nhau. Một cách ngây thơ, điều này có thể được thực hiện bằng cách mergegọi chuỗi :
df1.merge(df2, ...).merge(df3, ...)
Tuy nhiên, điều này nhanh chóng vượt khỏi tầm tay đối với nhiều DataFrames. Hơn nữa, có thể cần phải tổng quát hóa cho một số DataFrame chưa biết.
Ở đây tôi giới thiệu pd.concatcho các phép nối nhiều cách trên các khóa duy nhất và DataFrame.joincho phép nối nhiều cách trên các khóa không duy nhất . Đầu tiên, thiết lập.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Hợp nhất nhiều đường trên các khóa duy nhất (hoặc chỉ mục)
Nếu các khóa của bạn (ở đây, khóa có thể là một cột hoặc một chỉ mục) là duy nhất, thì bạn có thể sử dụng pd.concat. Lưu ý rằng pd.concatkết hợp DataFrames trên chỉ mục .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Bỏ qua join='inner'THAM GIA ĐẦY ĐỦ OUTER. Lưu ý rằng bạn không thể chỉ định các phép nối LEFT hoặc RIGHT OUTER (nếu bạn cần, hãy sử dụng join, mô tả bên dưới).
Hợp nhất nhiều đường trên các phím có bản sao
concatlà nhanh, nhưng có những thiếu sót của nó. Nó không thể xử lý các bản sao.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
Trong tình huống này, chúng ta có thể sử dụng joinvì nó có thể xử lý các khóa không phải là duy nhất (lưu ý rằng jointham gia DataFrames trên chỉ mục của chúng; nó gọi ẩn mergevà thực hiện LEFT OUTER JOIN trừ khi được chỉ định khác).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Một cái nhìn trực quan bổ sung về pd.concat([df0, df1], kwargs). Lưu ý rằng, ý nghĩa của kwarg axis=0hoặc axis=1'không trực quan bằng df.mean()hoặcdf.apply(func)
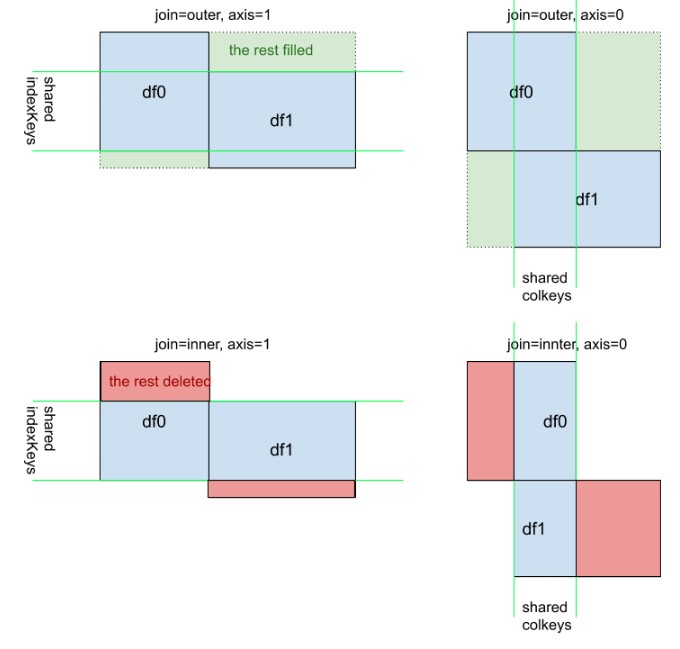
Trong câu trả lời này, tôi sẽ xem xét một ví dụ thực tế về pandas.concat.
Xem xét các cột sau DataFramescó cùng tên:
Preco2018 với kích thước (8784, 5)
Preco 2019 với kích thước (8760, 5)
Có cùng tên cột.
Bạn có thể kết hợp chúng bằng pandas.concatcách đơn giản
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
Kết quả là một DataFrame có kích thước sau (17544, 5)

Nếu bạn muốn hình dung, nó sẽ hoạt động như thế này
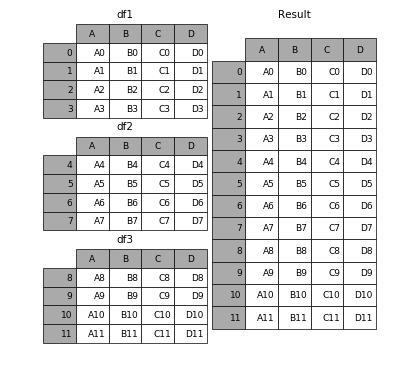
( Nguồn )