Kỹ thuật dữ liệu trở nên dễ dàng — Tập lệnh Python được đính kèm để bắt đầu Nhiệm vụ ETL của bạn
Tổng quan:
Đảm nhận công việc của một Kỹ sư dữ liệu, trích xuất dữ liệu từ nhiều nguồn định dạng tệp, chuyển đổi dữ liệu đó thành các loại dữ liệu cụ thể và tải dữ liệu đó vào một nguồn duy nhất để phân tích. Ngay sau khi đọc bài viết này, với sự trợ giúp của một số ví dụ thực tế, bạn sẽ có thể kiểm tra các kỹ năng của mình bằng cách triển khai quét web và trích xuất dữ liệu bằng API. Với Python và kỹ thuật dữ liệu, bạn sẽ có thể bắt đầu thu thập các bộ dữ liệu khổng lồ từ nhiều nguồn và biến chúng thành một nguồn chính duy nhất hoặc bắt đầu tìm kiếm trên web để có những hiểu biết hữu ích về kinh doanh.

Tóm tắt:
- Tại sao kỹ thuật dữ liệu đáng tin cậy hơn?
- Quy trình của chu trình ETL
- Từng bước Trích xuất, Chuyển đổi, chức năng Tải
- Giới thiệu về Kỹ thuật dữ liệu
- Phần kết luận
Đây là một nghề công nghệ đáng tin cậy hơn và phát triển nhanh nhất trong thế hệ hiện tại, vì nó tập trung nhiều hơn vào các tập dữ liệu thu thập dữ liệu và thu thập thông tin trên web.
Quy trình (Chu kỳ ETL):
Bạn đã bao giờ tự hỏi làm thế nào dữ liệu từ nhiều nguồn được tích hợp để tạo ra một nguồn thông tin duy nhất chưa? Xử lý hàng loạt là một loại thu thập dữ liệu và tìm hiểu thêm về “cách khám phá một loại xử lý hàng loạt” có tên là Trích xuất, Chuyển đổi và Tải.

ETL là quá trình trích xuất khối lượng dữ liệu khổng lồ từ nhiều nguồn và định dạng khác nhau và chuyển đổi nó thành một định dạng duy nhất trước khi đưa nó vào cơ sở dữ liệu hoặc tệp đích.
Một số dữ liệu của bạn được lưu trữ trong tệp CSV, trong khi những dữ liệu khác được lưu trữ trong tệp JSON. Bạn phải tập hợp tất cả thông tin này vào một tệp duy nhất để AI đọc. Vì dữ liệu của bạn ở dạng đơn vị đo lường Anh, nhưng AI lại cần đơn vị đo lường, nên bạn sẽ cần chuyển đổi dữ liệu đó. Vì AI chỉ có thể đọc dữ liệu CSV trong một tệp lớn nên trước tiên bạn phải tải tệp đó. Nếu dữ liệu ở định dạng CSV, hãy đặt ETL sau bằng python và xem xét bước trích xuất với một số ví dụ đơn giản.
Bằng cách xem danh sách các tệp.json và.csv. Phần mở rộng tệp toàn cầu được đặt trước bởi một ngôi sao và một dấu chấm trong đầu vào. Một danh sách các tệp .csv được trả về. Đối với các tệp .json, chúng ta có thể làm điều tương tự. Chúng tôi có thể tạo tệp trích xuất tên, chiều cao và trọng lượng ở định dạng CSV. Tên tệp của tệp .csv là đầu vào và đầu ra là một khung dữ liệu. Đối với các định dạng JSON, chúng ta cũng có thể làm điều tương tự.
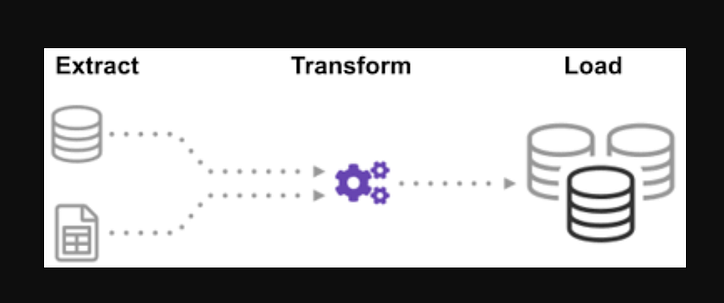
Bước 1:
Nhập các chức năng và mô-đun cần thiết
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Các tệp này dealership_datachứa các tệp CSV, JSON và XML cho dữ liệu ô tô đã qua sử dụng chứa các tính năng có tên car_model, year_of_manufacture, price, và fuel. Vì vậy, chúng tôi sẽ trích xuất tệp từ dữ liệu thô và chuyển đổi nó thành tệp đích và tải nó ở đầu ra.
Đặt đường dẫn cho các tệp đích:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
Chức năng sẽ trích xuất một lượng lớn dữ liệu từ nhiều nguồn theo đợt. Bằng cách thêm chức năng này, giờ đây nó sẽ khám phá và tải tất cả các tên tệp CSV, đồng thời các tệp CSV sẽ được thêm vào khung ngày với mỗi lần lặp lại vòng lặp, với lần lặp đầu tiên được đính kèm trước, sau đó là lần lặp thứ hai, kết quả là trong danh sách dữ liệu được trích xuất. Sau khi chúng tôi thu thập dữ liệu, chúng tôi sẽ chuyển sang bước "Chuyển đổi" của quy trình.
Lưu ý: Nếu "chỉ mục bỏ qua" được đặt thành true, thì thứ tự của mỗi hàng sẽ giống với thứ tự mà các hàng được thêm vào khung dữ liệu.
Chức năng trích xuất CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Bây giờ, hãy gọi hàm giải nén bằng lệnh gọi hàm của nó cho CSV , JSON , XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Sau khi chúng tôi thu thập dữ liệu, chúng tôi sẽ chuyển sang giai đoạn "Chuyển đổi" của quy trình. Hàm này sẽ chuyển đổi chiều cao của cột, tính bằng inch, sang milimét và cột pound, tính bằng pound, sang kilôgam và trả về kết quả ở dạng dữ liệu biến đổi. Trong khung dữ liệu đầu vào, chiều cao cột tính bằng feet. Chuyển đổi cột để chuyển đổi sang mét và làm tròn đến hai chữ số thập phân.
def transform(data):
data['price'] = round(data.price, 2)
return data
Đã đến lúc tải dữ liệu vào tệp mục tiêu mà chúng tôi đã thu thập và chỉ định nó. Chúng tôi lưu khung dữ liệu gấu trúc dưới dạng CSV trong trường hợp này. Bây giờ chúng ta đã trải qua các bước trích xuất, chuyển đổi và tải dữ liệu từ nhiều nguồn khác nhau vào một tệp đích duy nhất. Chúng ta cần thiết lập một mục ghi nhật ký trước khi có thể hoàn thành công việc của mình. Chúng tôi sẽ đạt được điều này bằng cách viết một chức năng ghi nhật ký.
Chức năng tải:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Tất cả dữ liệu được ghi sẽ được thêm vào thông tin hiện tại khi "a" được thêm vào. Sau đó, chúng tôi có thể đính kèm dấu thời gian cho từng giai đoạn của quy trình, cho biết khi nào nó bắt đầu và khi nào nó kết thúc, bằng cách tạo loại mục nhập này. Sau khi chúng tôi đã xác định tất cả mã cần thiết để thực hiện quy trình ETL trên dữ liệu, bước cuối cùng là gọi tất cả các chức năng.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Đầu tiên chúng ta bắt đầu bằng cách gọi hàm extract_data. Dữ liệu nhận được từ bước này sau đó sẽ được chuyển sang bước thứ hai là chuyển đổi dữ liệu. Sau khi hoàn thành, dữ liệu sẽ được tải vào tệp đích. Ngoài ra, lưu ý rằng trước và sau mỗi bước, thời gian và ngày bắt đầu và hoàn thành đã được thêm vào.
Nhật ký mà bạn đã bắt đầu quá trình ETL:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log("Giai đoạn chuyển đổi đã bắt đầu")
biến đổi dữ liệu = biến đổi (dữ liệu được trích xuất)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- Cách viết hàm Extract đơn giản.
- Cách viết hàm Transform đơn giản.
- Cách viết hàm Load đơn giản.
- Cách viết một chức năng ghi nhật ký đơn giản.
Nhiều nhất, chúng tôi đã thảo luận về tất cả các quy trình ETL. Hơn nữa, hãy xem, ” lợi ích của công việc kỹ sư dữ liệu là gì?”.
Về Kỹ thuật dữ liệu:
Kỹ thuật dữ liệu là một lĩnh vực rộng lớn với nhiều tên gọi. Nó thậm chí có thể không có một tiêu đề chính thức trong nhiều tổ chức. Do đó, tốt hơn hết là bắt đầu bằng cách xác định mục tiêu của công việc kỹ thuật dữ liệu dẫn đến kết quả đầu ra mong đợi. Người dùng dựa vào các kỹ sư dữ liệu cũng đa dạng như tài năng và kết quả của nhóm kỹ thuật dữ liệu. Người tiêu dùng của bạn sẽ luôn xác định những vấn đề bạn xử lý và cách bạn giải quyết chúng, bất kể bạn theo đuổi lĩnh vực nào.
Phần kết luận:
Tôi hy vọng bạn tìm thấy một số trợ giúp trong bài viết và hiểu được một số cách sử dụng Python sang ETL khi bạn bắt đầu hành trình tìm hiểu kỹ thuật dữ liệu. Cảm thấy muốn tìm hiểu thêm? Tôi khuyến khích bạn xem các bài viết khác của tôi về cách bạn có thể sử dụng các lớp python để cải thiện các quy trình kỹ thuật dữ liệu . Tôi cũng trình bày cách sử dụng pydantic để cải thiện việc xác thực dữ liệu của bạn ở một trong những bước đầu tiên và quan trọng nhất trong đường dẫn dữ liệu của bạn. Nếu bạn quan tâm đến trực quan hóa dữ liệu, hãy xem hướng dẫn từng bước này để tạo biểu đồ đầu tiên của bạn với Apache Superset .
Kêu gọi hành động
Nếu bạn thấy hướng dẫn hữu ích, hãy vỗ tay và làm theo tôi. Tham gia phương tiện thông qua liên kết này để truy cập vào tất cả các bài báo cao cấp của tôi và tất cả các nhà văn tuyệt vời khác ở đây trên phương tiện.
Tăng cấp mã hóa
Cảm ơn vì đã là một phần của cộng đồng của chúng tôi! Trước khi bạn đi:
- Vỗ tay cho truyện và theo dõi tác giả
- Xem thêm nội dung trong ấn phẩm Level Up Coding
- Theo dõi chúng tôi: Twitter | LinkedIn | bản tin

![Dù sao thì một danh sách được liên kết là gì? [Phần 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































