Tại sao phải trả nhiều tiền hơn cho Machine Learning?

Tăng tốc khối lượng công việc học tập mất cân bằng của bạn với Tiện ích mở rộng Intel dành cho Scikit-learning
Ethan Glaser, Nikolay Petrov, Henry Gabb và Jui Mhatre, Tập đoàn Intel
Một blog NVIDIA gần đây đã thu hút sự chú ý của chúng tôi với các kết quả sai lệch của nó . Điểm quan trọng của việc so sánh GPU A100 với CPU chín năm tuổi (Intel Xeon E5–2698 được ra mắt vào năm 2014 và kể từ đó đã bị ngừng sản xuất) hoặc so sánh mã CUDA được tối ưu hóa (thư viện RAPIDS cuML) với mã đơn luồng chưa được tối ưu hóa Mã Python (stock scikit-learning với thư viện tìm hiểu mất cân bằng ) trừ khi bạn đang cố tình tăng tốc GPU so với tăng tốc CPU? Thư viện tìm hiểu mất cân bằng hỗ trợ các công cụ ước tính tương thích với scikit-learning, vì vậy họ đã sử dụng các công cụ ước tính cuML để tăng tốc. Chúng tôi có thể sử dụng các công cụ ước tính được tối ưu hóa trong Tiện ích mở rộng Intel cho Scikit-learning chỉ bằng cách thêm lệnh gọi tới patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

So sánh hiệu suất
Tiện ích mở rộng của Intel dành cho Scikit-learning giúp tăng tốc toàn diện cho cùng điểm chuẩn như Nvidia (Hình 1). Phạm vi tăng tốc từ ~2x đến ~140x tùy thuộc vào thuật toán và thông số. Lưu ý rằng thư viện scikit-learning stock đã hết bộ nhớ cho điểm chuẩn SMOTE và ADASYN “100 tính năng, 5 lớp”. Nếu vấn đề về hiệu suất, những kết quả này chứng minh rằng Tiện ích mở rộng của Intel dành cho Scikit-learning mang lại khả năng tăng tốc đáng kể so với scikit-learning nguyên bản.

Điều này so sánh với kết quả A100 của Nvidia như thế nào? Chúng ta hãy xem xét hai thuật toán mà Nvidia đạt được tốc độ cao nhất qua scikit-learning: SVMSMOTE và CondensedNearestNeighbours (Hình 2). Những kết quả này cho thấy rằng hiệu suất của chúng tôi có mức độ tương tự như cuML khi bộ xử lý mới hơn và scikit-learning được tối ưu hóa được sử dụng để so sánh. Phần mở rộng Intel cho Scikit-learning thậm chí còn vượt trội hơn cuML trong một số thử nghiệm. Bây giờ, hãy nói về giá cả.


So sánh chi phí
Cần lưu ý rằng chi phí mỗi giờ của phiên bản a2-highgpu-1g A100 trên GCP cao hơn 60% so với phiên bản n2-highcpu-64 (Bảng 1). Điều đó có nghĩa là phiên bản A100 phải tăng tốc ít nhất 1,6 lần so với phiên bản Xeon Gold 6268CL (n2-highcpu-64) để có mức chi phí cạnh tranh. (Một chiếc A100 cũng tiêu thụ nhiều điện năng hơn 1,7 lần và 1,2 lần so với Xeon E5–2696 v4 và Xeon Gold 6268CL, nhưng chúng tôi tạm gác vấn đề đó sang một bên vì mức tiêu thụ điện năng đã được tính vào chi phí phiên bản.)
Hãy so sánh tỷ lệ giá trên hiệu suất đối với các điểm chuẩn do Nvidia chọn để xem liệu phiên bản A100 có phù hợp với mức giá cao cấp của nó hay không. Tổng chi phí (USD) của một lần chạy điểm chuẩn chỉ đơn giản là chi phí phiên bản mỗi giờ (USD/giờ) nhân với thời gian chạy (giờ). Một so sánh chi tiết về chi phí cho thấy chạy các điểm chuẩn này trên phiên bản Xeon thường là tùy chọn tiết kiệm chi phí hơn (Hình 3). Trong các biểu đồ bên dưới, giá trị lớn hơn một cho biết điểm chuẩn nhất định đắt hơn trên phiên bản A100. Ví dụ: giá trị 1,29 có nghĩa là phiên bản A100 đắt hơn 29% so với phiên bản Xeon.



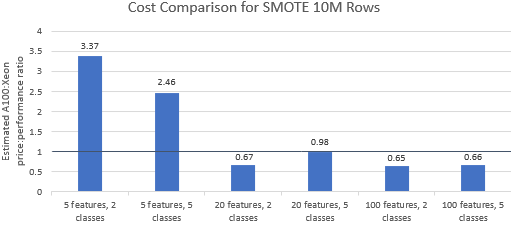
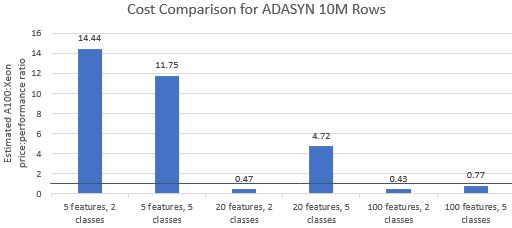
Chi phí điểm chuẩn khác nhau tùy thuộc vào thuật toán và tham số được sử dụng, nhưng kết quả thường nghiêng về ví dụ Xeon: giá trị trung bình hình học của chi phí lớn hơn một đối với bốn trong số năm thuật toán và giá trị trung bình hình học tổng thể là 1,36 (Bảng 2).

Ngoài ra, CPU mang lại sự linh hoạt hơn trong việc lựa chọn phiên bản, giúp cải thiện hiệu quả hơn nữa. Sẽ tiết kiệm chi phí hơn nếu chọn phiên bản Xeon có khả năng nhỏ nhất có thể xử lý quy mô sự cố nhất định trong khi vẫn đáp ứng các yêu cầu về hiệu suất và hạn chế về ngân sách. Hình 4 cho thấy một ví dụ như vậy đối với hai điểm chuẩn nhỏ nhất. Những kết quả này chứng minh rằng nó có thể rẻ hơn đáng kể khi chạy trên phần cứng phù hợp nhất với nhu cầu của cấu hình mô hình. Ví dụ: chạy hai điểm chuẩn ADASYN với Tiện ích mở rộng Intel dành cho Scikit-learning trên phiên bản e2-highcpu-8 chỉ bằng 1,5% và 2,1% chi phí chạy cuML trên phiên bản A100.

Phần kết luận
Các kết quả trên chứng minh rằng Tiện ích mở rộng Intel dành cho Scikit-learning có khả năng cải thiện đáng kể kết quả hoạt động so với scikit-learning nguyên bản và cũng có khả năng vượt trội hơn A100 trong một số thử nghiệm. Khi tính đến chi phí, phần mở rộng Intel cho kết quả tìm hiểu Scikit thậm chí còn thuận lợi hơn vì các phiên bản Xeon rẻ hơn rất nhiều so với phiên bản A100. Người dùng có thể chọn một phiên bản Xeon đáp ứng các yêu cầu về hiệu suất, sức mạnh và giá của họ.

![Dù sao thì một danh sách được liên kết là gì? [Phần 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































